算法 #3期:分治算法在海量数据处理问题上的使用
案例 🔗︎
我们有1TB的订单数据,需要按照金额大小排序。而机器内存只有2G。如何解决这个问题?
分析 🔗︎
这是一个海量数据处理问题,针对这一类的思路可以通过分治思想,就像我们的标题说的那样。 什么是分治思想,简单来说就是把一个问题拆解成更小的类似问题,分别解决这些小问题, 最后把小问题结果合并得到最终的结果。 这样说有点抽象,我们可以从归并排序这个案例去理解分治思想,因为这个案例比较简单。
归并排序是简单来说,就是把对一组数字不断的分解下去,直到最后一组只剩1个数字认为是已排序,然后把每组再合并起来最终得到结果:
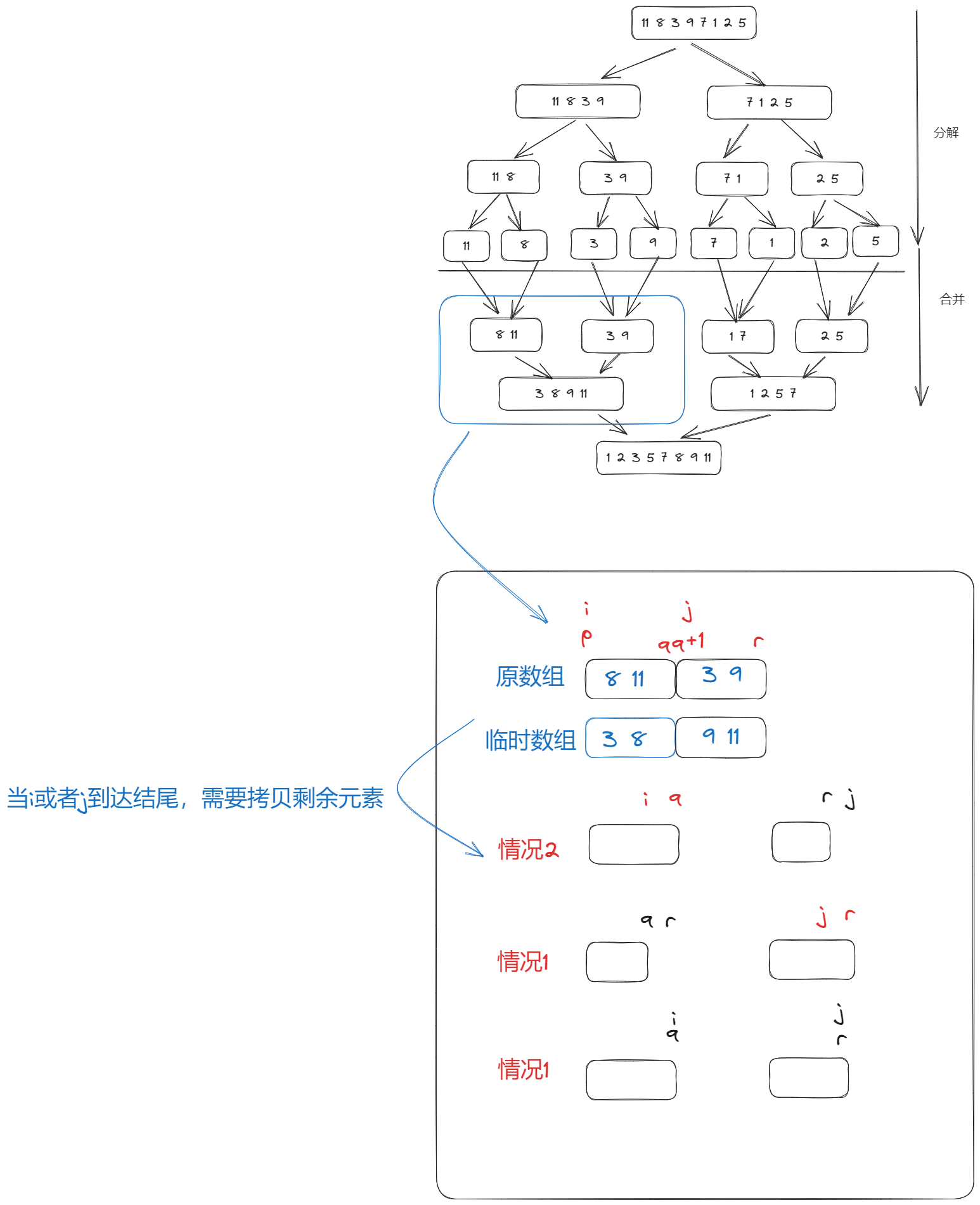
归并排序的过程
这个分解和合并的过程就是分治的思想。其中,如何合并是最为关键的,合并的结果必须是按照升序排序。合并的过程的也非常简单:假设是数组A, 数组B合并,每次合并前申请一个新数组(数组大小是A+B)。然后用两个游标分别指向A和B, 并且将小的那个复制到新数组中,并且移动它的游标。 如果游标到数组末尾,则停止比较,并将剩余元素复制到新数组(这里会存在两种情况,参考图解),最后将新数组复制到原数据(会改变原数组的内容)。
所以整个归并排序的过程,只有两个数组,一个是原数组,一个是合并过程的过程数组。游标都是指向原数组。
const mergeSort = (data, p, r) => {
// 如果只剩一个元素,结束循环
if(p >= r) return;
// 暂且以中间为分割
let q = Math.floor((p + r) / 2);
// 分解
mergeSort(data, p, q)
mergeSort(data, q + 1, r)
// 合并
merge(data, p, q, r)
}
const merge = (data, p, q, r) => {
const temp = new Array(r-p+1);
let i = p;
let j = q+1;
let k = 0;
while(i<=q && j <= r) {
if(data[i] <= data[j]) {
temp[k++] = data[i++]
}
else {
temp[k++] =data[j++]
}
}
// 判断哪个数组中有剩余数据
let start = i;
let end = r;
if(j>r) {
end = q
}
else {
start = j
}
while(start <= end) {
temp[k++] = data[start++]
}
// 将temp复制回去
for(let i=0;i<r-p+1; i++) {
data[p+i] = temp[i]
}
return data;
}
export const ms_test_function = () => {
const data = [11,8,3,9,7,1,2,3]
mergeSort(data, 0, data.length - 1)
return true;
}
回到正题。面对大量的订单数据如何排序,机器内存不足如何排序。
1、首先要把这个大文件逐行读取到小文件。小文件怎么拆分呢。主要是需要根据订单的金额。比如订单金额最大是1万,我们就根据金额拆分0-99, 100-199, 200-299… 0到99就放到文件0当中,100-199就放到1文件中,依次类推。为什么要根据金额拆分文件。主要是便于后面合并小文件的时候,可以根据文件名的大小进行排序。
// Step 1: Divide the file into smaller partitions based on order amounts
function partitionFile(inputFilePath, outputDirPath, callback) {
const partitions = {};
// Read the input file sequentially
const readStream = fs.createReadStream(inputFilePath, { encoding: 'utf8' });
readStream.on('data', (chunk) => {
const orders = chunk.split('\n');
orders.forEach((order) => {
// Extract the order amount from the order entry
const amount = parseFloat(order.split(',')[1]);
// Determine the partition for the order based on its amount
const partition = Math.floor(amount / 100);
// Create a writable stream for the partition file if it doesn't exist
if (!partitions.hasOwnProperty(partition)) {
const partitionFilePath = `${outputDirPath}/partition_${partition}.txt`;
partitions[partition] = fs.createWriteStream(partitionFilePath, { flags: 'a' });
}
// Write the order to the appropriate partition file
partitions[partition].write(`${order}\n`);
});
});
readStream.on('end', () => {
// Close all partition files
for (const partition in partitions) {
partitions[partition].end();
}
callback();
});
}
2、每个小文件在内存中排序(这里可以通过一台电脑处理,也可以通过多台电脑并行处理,像google的MapReduce的思路一样,能加快处理速度,当然这里还涉及到机器的调度问题),并且写回小文件
// Step 2: Sort each partition individually
function sortPartitions(inputDirPath, outputDirPath, callback) {
fs.readdir(inputDirPath, (err, files) => {
if (err) {
throw err;
}
files.forEach((file) => {
const filePath = `${inputDirPath}/${file}`;
const sortedFilePath = `${outputDirPath}/sorted_${file}`;
// Read the orders from the partition file
const orders = fs.readFileSync(filePath, { encoding: 'utf8' }).split('\n');
// Sort the orders using an efficient algorithm (e.g., merge sort)
const sortedOrders = orders.sort((a, b) => {
const amountA = parseFloat(a.split(',')[1]);
const amountB = parseFloat(b.split(',')[1]);
return amountA - amountB;
});
// Write the sorted orders to the sorted partition file
fs.writeFileSync(sortedFilePath, sortedOrders.join('\n'), { encoding: 'utf8' });
});
callback();
});
}
3、将小文件根据文件名按照归并排序的合并成大文件。这样就完成了整个文件的排序。
// Step 3: Merge the sorted partitions
function mergePartitions(inputDirPath, outputFilePath) {
// Step 1: Perform merge sort on an array of numbers
function mergeSort(arr) {
if (arr.length <= 1) {
return arr;
}
const mid = Math.floor(arr.length / 2);
const left = arr.slice(0, mid);
const right = arr.slice(mid);
return merge(mergeSort(left), mergeSort(right));
}
// Step 2: Merge two sorted arrays
function merge(left, right) {
let merged = [];
let i = 0;
let j = 0;
while (i < left.length && j < right.length) {
// 读取文件标题后面的数字
if (parseFloat(left[i].split(',')[1]) <= parseFloat(right[j].split(',')[1])) {
merged.push(left[i]);
i++;
} else {
merged.push(right[j]);
j++;
}
}
while (i < left.length) {
merged.push(left[i]);
i++;
}
while (j < right.length) {
merged.push(right[j]);
j++;
}
return merged;
}
const filePointers = [];
let mergedOutput = '';
fs.readdir(inputDirPath, (err, files) => {
if (err) {
throw err;
}
// Open all sorted partition files and initialize file pointers
files.forEach((file) => {
const filePath = path.join(inputDirPath, file);
const fileData = fs.readFileSync(filePath, 'utf8').trim();
const partitionData = fileData.split('\n');
filePointers.push(partitionData);
});
// Merge the sorted partitions
const sortedOutput = mergeSort(filePointers.flat());
// Format the sorted output
mergedOutput = sortedOutput.join('\n') + '\n';
// Write the merged output to the final sorted file
fs.writeFileSync(outputFilePath, mergedOutput, { encoding: 'utf8' });
// Delete the temporary partition files
// files.forEach((file) => {
// const filePath = path.join(inputDirPath, file);
// fs.unlinkSync(filePath);
// });
});
}
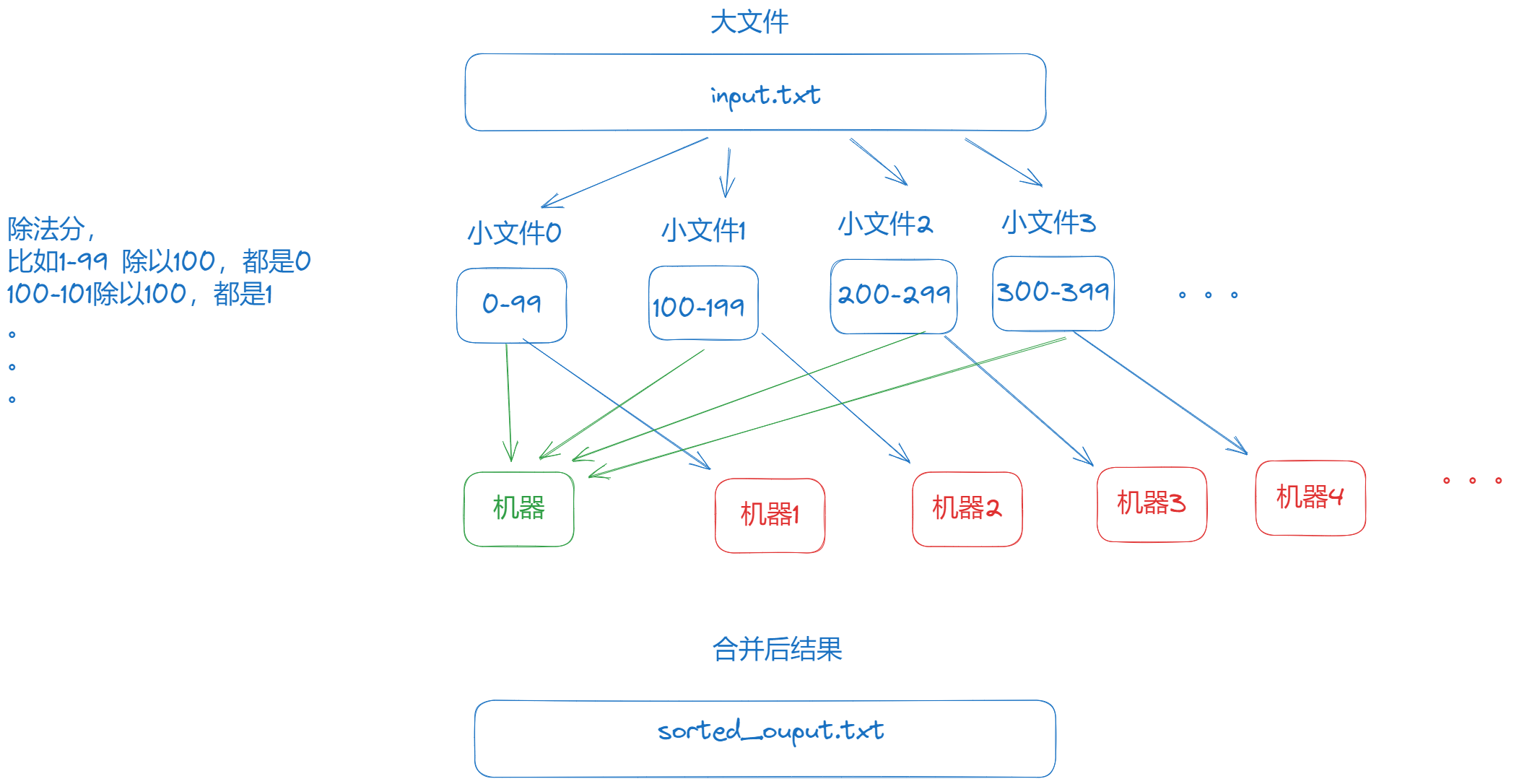
分治过程
运行结果 🔗︎
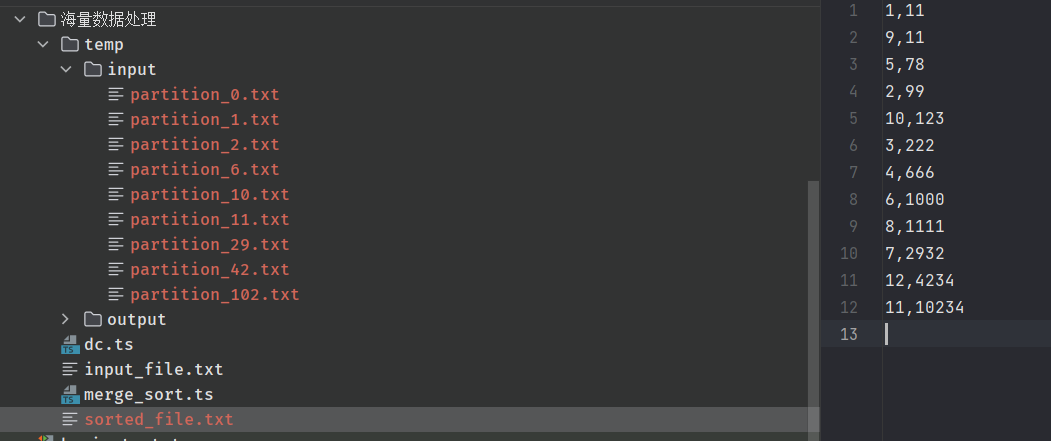
运行结果
temp目录input是分小文件后的结果,每个小文件存储对应的订单数据,output是小文件内部排序后的结果,最后sorted_file.txt是最终的合并结果,可以看到已经排序好了。