AI 你需要知道的
AI 认知 🔗︎
机器学习 > 人工神经网络 > 深度学习 > 大模型 是一个包含关系
机器学习 🔗︎
假设一个案例是计算分数,w 是最终的分数,x 命中特征为 1,x 未命中特征为 0 f(x) = wx, w 是参数 , 训练模型就是为了得到这个参数,也就是怎么合理分配权重。 特征工程: 将特征 x 转为数字, 因为有些特征不一定就是数字。
机器学习里的样本就是范例,给到机器(代码)去训练, label 就是范例的结果是什么,加了 label 的是监督学习,没有的 label 的是无监督学习
模型预训练:
1、准备样本 -> 收集资料
2、特征工程: 得到 x
3、设计模型:f(x) = wx -> 学习计划
4、训练模型: 得到 y -> 学习过程
5、测评
文本特征提取: 向量: [1 0 0 0 0 0 ] 类似这种的东西,只有 1 个 1 的叫 one-shot 词汇表有 5 万词,“苹果”是第 3 个词 → 向量为 [0,0,1,0,…,0](长度 5 万,仅第 3 位为 1)。
embedding: 本质也是一个向量,是对 one-shot 向量的优化: 不再只用 0 和 1 表达数据,对文本的词有语义表示;压缩了向量的纬度
模型任务: 回归表示不可枚举的任务,输出为连续数值; 可枚举的任务为分类,输出为离散标签。 模型选择: LR 模型
模型训练: 拟合 无限接近的现象,就是计算机计算的结果要和打标的结果要一致。 好的模型要有泛化能力, 而不是过拟合, 或者欠拟合。 超参数 非模块学习得到的参数,是通过人工干预的。可以控制模型学习的速度和性能,比如学习轮次/批次大小/学习速度/优化算法/损失函数。
典型的学习过程: 把数据/题目分批(batch),学完再测试验证(loss),看错哪里了。然后优化算法告诉你错哪里了,要怎么调整学习思路(参数),继续学。直到把所有题目学完(1 epoch)。 如果不够,重复再来一轮。
数据集分类: 训练集 验证集 测试集
训练效果验证: k-fold 验证 测试: 通过混淆矩阵 来判定模型是否通过测试,核心指标 acc, f1, auc
LR 模型: 经典的分类模型。简单来说,它通过计算概率来判断输入数据属于哪一类别(比如判断邮件是“垃圾邮件”还是“正常邮件”)。可解释性强, 权重 w 和正负直接反应对结果的影响
深度学习 🔗︎
relu: Rectified Linear Unit 激活函数
激活函数就像“智能开关”
它决定一个神经元(神经网络中的小计算单元)是否要把接收到的信号传递出去。比如:
- 如果信号强,开关就打开,让信号继续传递;
- 如果信号弱,开关就关闭,阻止信号传递。
为什么需要它?
- 加入“非线性”:没有激活函数,神经网络只能处理像直线分割的简单问题(比如区分红蓝点画一条直线)。有了它,才能处理像曲线、图像、语言等复杂问题。
- 控制输出范围:比如有的激活函数把输出限制在 0 到 1 之间(像开关),有的允许负数(像双向开关)。
常见激活函数
- Sigmoid:把输入压缩到 0~1,类似“概率”(但容易导致梯度消失,现在少用)。
→ 比如判断“是不是猫”,输出 0.8 表示 80%可能是猫。 sigmoid 工具将 Linear Regression 变成 Logistic Regression - ReLU:简单粗暴——输入大于 0 时原样输出,小于 0 时输出 0(最常用,缓解梯度消失)。
→ 比如输入 10,输出 10;输入-5,输出 0。 - Tanh:类似 Sigmoid,但输出范围-1~1(适合需要负值的场景)。
类比:
想象你是一个水管工,神经网络是一堆水管。激活函数就是每个连接处的阀门——有的阀门只允许水流单向通过(ReLU),有的可以调节水流大小(Sigmoid),这样整个水管系统才能灵活适应不同地形(复杂数据)。
MLP: Multi-layer Perceptron 前馈神经网络(反之,就是反馈神经网络 RNN) 输入一张猫的图片 → 隐藏层分析耳朵形状、胡须等特征 → 输出层判断“是猫”。 MLP 加入隐藏层和激活函数,突破了线性限制,能拟合更复杂的函数。
表征学习: 图片表征 -> CNN 句子本质是 N _ 1 的数据,有一个滑动窗口提取 token,图片是 N _ M 文本表征 -> word2vec
窗口大小:假设为 2N+1(如 N=2,则窗口大小为 5 个词)。
CBOW 模式(连续词袋):
- 输入:窗口内除中心词外的上下文词(共 2N 个词)。
- 输出(目标):预测中心词。
- 处理方式:输入的所有上下文词向量取平均,作为整体输入特征。
- 示例:
句子:“今天/天气/晴朗/适合/散步”
窗口滑动到“天气/晴朗/适合” → 输入“天气”和“适合”,输出目标“晴朗”。
Skip-gram 模式:
- 输入:中心词。
- 输出(目标):预测窗口内的所有上下文词(2N 个词)。
- 示例:
同一句子中,输入“晴朗”,输出预测“天气”和“适合”。
模型会自动调整词向量, 想象你在教一个机器人投篮。 机器人一开始乱投(词向量随机初始化)。 每次投篮后,你告诉它偏离目标多远(计算损失函数)。 机器人根据偏差自动调整手臂角度(反向传播更新参数)。 反复练习后,投篮越来越准(词向量逐步优化)。
这个也解释了为什么需要大量计算,需要大量芯片。
图谱表征: deepwalk 和 gcn
单独用 MLP 处理不了时序数据: 每次输入的样本独立处理,无法保留之前的上下文信息。
- 输入句子“我喜欢吃苹果”,MLP 若将每个词单独输入,无法知道“苹果”前面有“吃”,可能误判为“苹果公司”的电子设备。
RNN/LSTM 以及 Transformer 在时序数据能力方面 优秀
RNN: encoder-decoder 先理解再输出,不是边理解边输出 Transformer(来自 seq2seq) 用了自注意力机制和 Multi-head Attention: Transformer 是一个组件,多个组件,相当于多个朋友给建议
Encoder-Decoder: Encoder 读完整个句子,生成总结向量。 Decoder 翻译时,可能混淆“卡皮巴拉”和“动物”的位置关系。
注意力机制: 翻译“capybara”时,模型自动关注输入中的“卡皮巴拉”; 翻译“is an animal”时,关注“动物”。
transformer 创造: one-shot 然后把特征数据输入到 self-attention 做表征学习, 然后输出到 MLP 学习,最后用 liner 压缩 最后 softmax 判断词的概率
- “One-Shot 输入”
- 一次性输入整个序列(而非逐词处理)。
- 实际机制:
- ✅ 并行性:Transformer 通过 并行处理 所有位置的词(如输入句子全部同时处理),这点正确。
- ❌ “One-Shot” 术语:技术上更准确的术语是 “非自回归”(Non-Autoregressive) 或 “并行输入”,但核心思想一致。
- “输入到 Self-Attention 做表征学习”
- 用自注意力机制学习上下文特征。
- 实际机制:
- ✅ 自注意力(Self-Attention):核心组件,通过计算词与词之间的关联权重,动态聚合全局信息(例如“猫”关注“吃”和“鱼”)。
- 🔄 多头注意力(Multi-Head):实际中会拆分为多个“头”(如 8 个),每个头学习不同的关注模式,最后拼接结果。
- ❗ 位置编码(Positional Encoding):输入前必须添加位置编码(如正弦波),否则模型无法感知词序(如“猫追狗”和“狗追猫”会被视为相同)。
- “输出到 MLP 学习”
- 用多层感知机(MLP)进一步学习特征。
- 实际机制:
- ✅ 前馈网络(FFN):每个注意力层后接一个 FFN(即 MLP),通常包含两个线性层和激活函数(如 ReLU),用于非线性变换。
- 🔄 残差连接 & 层归一化:每个子层(注意力或 FFN)的输出会与输入相加(残差连接),再经过层归一化(LayerNorm),防止梯度消失并加速收敛。
- “线性压缩 + Softmax 判断词概率”
- 用线性层映射到词表大小,Softmax 生成概率分布。
- 实际机制:
- ✅ 线性投影:最后一层输出的隐藏状态通过线性层(如
d_model → vocab_size)压缩到词表维度。 - ✅ Softmax:输出每个词的概率,用于预测下一个词。
- ✅ 线性投影:最后一层输出的隐藏状态通过线性层(如
相关概念: 残差连接(Residual Connection)和层归一化(Layer Normalization)
- 问题背景:网络越深,梯度容易消失(反向传播时梯度趋近于零,无法更新参数)。
- 残差连接:将输入直接加到注意力层的输出上(即
输出 = 输入 + 注意力结果)。- 作用:相当于给梯度开“绿色通道”,避免深层网络中梯度消失。
- 层归一化:对每一层的输出做归一化(均值 0,方差 1),稳定训练过程。
- 类比:就像考试前老师统一调整分数,让不同学生的成绩分布更稳定。
位置编码(Positional Encoding)
- 问题背景:Transformer 没有 RNN 的循环结构,无法天然感知词序(比如“猫追狗”和“狗追猫”含义不同)。
- 解决方法:给每个词的位置编号(比如第 1、2、3 个词),生成位置向量,和词嵌入相加。
- 直观理解:就像给每个词贴一个“坐标贴纸”,告诉模型它出现在序列的哪个位置。
- 公式:使用正弦/余弦函数生成位置编码,确保模型能处理任意长度的序列。
掩码多头注意力(Masked Multi-Head Attention)
- 问题背景:在生成任务(如翻译、文本生成)时,解码器预测第
t个词时不能看到后面的词(否则相当于作弊)。 - 解决方法:在注意力权重计算时,对后续词的位置加上“掩码”(设为负无穷),使 Softmax 后权重为 0。
- 例子:生成“I love cats”时,预测“cats”时只能看到“I”和“love”,看不到“cats”自身。
transformer 是算法,但是在实际应用中,Transformer 需要结合硬件(如 GPU/TPU)、分布式训练框架、高效计算库(如 CUDA)等工程优化才能高效运行。而具体落地(如 GPT、BERT)需要工程实现。
Encoder 负责理解输入,Decoder 负责生成输出,二者协作完成复杂任务(如翻译)。
预训练模型 🔗︎
无监督学习的模型
NLP 的问题: 没有泛化能力
Generative pre-training GPT 的名字由来。
GPT2: zero-shot 通过 prompt 将任务描述直接拼接在输入文本中,引导模型生成符合任务要求的输出
GPT3: few-shot
ChatGPT: InstructGPT 指令对齐模型,增加了安全性 。 引入 RLHF(Reinforcement Learning from Human Feedback) 人类反馈强化学习
- SFT 监督微调 -> 用人工标注的高质量问答数据对预训练大模型进行微调,类似于"教师示范教学"
- RM 奖励模型 -> 训练一个能判断回答质量的评分模型(例如用人类对回答的偏好排序数据训练),相当于建立"评分标准"
- PPO 强化学习 -> 让 SFT 模型生成多个回答,用 RM 模型评分作为反馈信号,通过强化学习算法持续优化,类似"学生根据评价不断改进" GPT o1: COT(chain of thought) 模型自己生成 chain of thought 不用人去告诉他。 这类就是推理大模型
Scaling law : 规模越大 效果越好 但有限度。 test-time scaling law: 推理计算量越大 效果越好
DeepSeek R1: 底层是多个模型
可行性 + 路线 🔗︎
数据处理架构 + 系统工程 + 应用的范式是不确定的,是小企业家的机会,补齐模型做不了的事情,底部是非常多的模型。但是模型和算法的范式是确定的,是大企业做的事。大模型蒸馏方式变成小模型效果比不过从 0 开始训练小模型。
数据抓取 - 清洗 - 然后做个应用 (cursor 内部是集成了 agent,不仅仅是模型知识和推理,而是有能力了)
不要被范式限制: 而是考虑它能做什么,去体验它。 比如通过模型识别意图,然后通过抠图工具实现抠图,然后再通过 xx 实现什么,这是一个 pipeline, 数据+工程+算法全栈都可以做,能力不一定 100%有 50%就 OK, 我的底线很低我可以提升一下不管别人怎样,不一定要用大语言模型
Faas 是一个服务,或者 servless 是服务,那么文本也可以成为服务: 每天给我推送 5 条 AI 消息,只能是英文并且。。 最后执行任务,然后发布到公众号,可以成为一个服务。可以自己实现代码,成为一个服务。 代码是生产力。
选出垂直场景,而不是单点解决
agent vs copilot 🔗︎
agent 有环境感知,制定计划,执行任务,然后完成目标(主驾)。 copilot 是助手,你给指令,然后帮你完成任务,这是需要 prompt 能力,需要探索,还需要业务场景能力。
模型不是能回答所有问题的 ,比如 训练的时候时间是什么时候,知识有欠缺,肯定回答不上来。->
所以一般需要结合 api 然后回答(compound ai sys / agentic system) -> 固定的 pipeline
范式 🔗︎
- Agents -> llm 基于任务目标、环境信息动态做决策 ,流程是不确定
- 单 agent
- 多 agent: 主从模式(主模式规划分派任务)/平等协作模式 (都可以决策,给谁做)
- computer use / web agent : 自动化测试指令是自动生成的, 这个区别是指令是 agent 动态生成的
1. 统计+数据 ≠ 真正的智能 🔗︎
1.1 数据驱动的局限性 🔗︎
- 依赖统计模型:当前的许多人工智能系统主要基于统计学和大数据分析,通过海量数据训练模型来完成特定任务。
- 缺乏真正理解:这些系统虽然能够处理复杂问题,但它们并不具备人类的“理解”能力。它们只是根据输入数据生成输出结果,而无法解释“为什么这么做”。
1.2 黑箱问题 🔗︎
- 不可解释性:随着深度学习等技术的发展,人工智能的决策过程变得越来越复杂,甚至人类开发者也无法完全理解其内部机制。
- 信任危机:这种“黑箱”特性使得人工智能在某些关键领域(如医疗、法律)的应用面临挑战。
2. 人工智能的层次划分 🔗︎
为了更好地理解人工智能的构成和应用,可以将其划分为以下五个层次:
2.1 基础设施 🔗︎
- 硬件支持:包括高性能计算设备(如 GPU、TPU)、云计算平台以及传感器等硬件设施。
- 数据资源:海量数据是人工智能的基础,数据的质量和多样性直接影响模型的效果。
2.2 算法 🔗︎
- 核心逻辑:算法是人工智能的核心,决定了系统的运行方式。常见的算法包括机器学习、深度学习、强化学习等。
- 优化与创新:不断优化现有算法并开发新的算法,是推动人工智能进步的关键。
2.3 技术 🔗︎
- 通用能力:这一层关注人工智能的具体技术实现,例如自然语言处理(NLP)、计算机视觉、语音识别等。
- 跨领域融合:这些技术可以应用于多个行业,并为后续解决方案提供技术支持。
2.4 技术点 🔗︎
- 细分功能:技术点是对技术的进一步细化,例如情感分析、图像分割、推荐系统等。
- 模块化设计:将复杂的技术分解为独立的功能模块,便于开发和集成。
2.5 行业解决方案 🔗︎
- 场景落地:最终目标是将人工智能技术应用于具体的行业场景,例如智慧医疗、自动驾驶、金融科技等。
- 定制化服务:根据不同行业的需求,提供针对性的解决方案,解决实际问题。
GPT 能做什么 🔗︎
核心能力 🔗︎
- 授业解惑
- 无私心、耐心,能够提供清晰且易于理解的答案。
- 具备类比、预测和按步骤输出的能力,适合教学和指导场景。
高级能力 🔗︎
理解复杂想法
- 语言翻译、语气和风格的翻译、跨领域翻译。
- 理解复杂的概念(如人类的笑话)并生成相关内容。
空间与视觉能力
- 结合工具(如 Stable Diffusion)生成符合预期的图片。
- 通过文本描述生成小人或简单的视觉内容。
3D 模型能力
- 支持生成或描述 3D 模型的基础信息。
代码理解能力
- 能够通过多个步骤组合工具实现用户意图,提供解决方案。
数学能力
- 解法正确,支持基础到中等难度的数学问题求解。
与世界交互
- 调用 API、发送邮件、浏览网页等,具备一定的任务执行能力。
实体交互
- 尽管无法直接看到或执行动作,但可以通过语言接口理解环境、任务、行动和反馈。
与人类交互
- 推理他人心理状态的能力强,能够根据上下文生成符合人类期望的内容。
GPT 的缺陷 🔗︎
尽管 GPT 功能强大,但仍存在一些局限性:
缺乏计划性
- 在文本生成时缺乏全局规划能力,尤其在需要心算或多步推理时表现较弱(自回归模型的固有限制)。
固化模型
- 模型一旦训练完成就无法快速学习或从经验中归纳总结,缺乏动态调整能力。
因果推理不足
- 对于需要溯因推理的问题,模型可能无法提供准确答案。
如何与 GPT 交互 🔗︎
非结构化数据的结构化
- 将复杂、模糊的需求转化为清晰、结构化的输入,提高模型的理解和输出质量。
One-shot 学习
- 提供知识背景和已知条件,明确求解目标,帮助模型快速生成解决方案。
结合外部工具
- 利用 API 调用、插件或其他工具扩展 GPT 的功能,解决特定领域的复杂问题。
未来的机会在哪 🔗︎
AI 的机会 🔗︎
快速数字化
- 降低物理建模的成本,将非结构化数据转化为结构化数据。
助手革命
- 一切都可以从“助手”角度出发,专注于解决问题,而非单纯追求便宜或效率。
抖音 vs 快手案例 🔗︎
- 抖音的成功在于让普通用户通过视频+音频快速发布内容,而非依赖算法优化。这说明了简单易用的工具在高频场景下的巨大潜力。
场景特征 🔗︎
广泛性
- 应用场景覆盖多个领域,包括教育、医疗、娱乐等。
高频使用
- 用户需求频繁,能够快速获得反馈。
快速反馈
- 输出结果即时可见,便于迭代优化。
目的函数明确
- 每次交互都有明确的目标,减少歧义。
中低决策维度
- 大多数任务不需要复杂的多维决策,适合当前 AI 的能力范围。
GPT 为什么这么厉害 🔗︎
基于概率和特征的语言模型 🔗︎
- GPT 基于概率和特征进行建模,而非传统的标记化方法。例如,“我在北京天(安门)天(气)”这种模式识别能力体现了其对语言深层次结构的理解。
语言承载智慧 🔗︎
- 语言是人类智慧的载体,GPT 通过多层结构压缩和学习这些信息,从而具备了跨领域的理解和生成能力。
当前两种主要模式 🔗︎
Fine-tune(调优)
- 不做标记,通过微调适应特定任务。
超文本模型
- 知识库无需调优,直接利用预训练模型生成内容。
Long-chain 的可能性 🔗︎
- Long-chain(长链推理)可能是未来发展方向之一,进一步提升模型在复杂任务中的表现。
如何写好提示词 🔗︎
以下是关于信息分类、信息提取、个性化回复以及总结的 Prompt 范例
信息分类 🔗︎
任务描述 🔗︎
您是一个银行客户服务机器人,需要根据客户提问的内容将其分类到预定义的类别中。如果提问无法归类到以下类别,则归为 customer service。
预定义类别 🔗︎
card arrivalchange pinexchange ratecountry supportcancel transfercharge dispute
规则 🔗︎
- 只需返回分类结果,无需解释或备注。
- 示例格式如下:
Inquiry: How do I know if I will get my card, or if it is lost?
Category: card arrival
Inquiry: I am planning an international trip to Paris and would like to know the exchange rate.
Category: exchange rate
Inquiry: What countries are getting support? I will be traveling soon.
Category: country support
Inquiry: Can I get help starting my computer? I am having difficulty.
Category: customer service
信息提取 🔗︎
任务描述 🔗︎
从提供的医疗记录中提取相关信息,并以 JSON 格式返回。
JSON Schema 🔗︎
{
"age": {
"type": "integer"
},
"gender": {
"type": "string",
"enum": ["male", "female", "other"]
},
"diagnosis": {
"type": "string",
"enum": ["migraine", "diabetes", "arthritis", "acne"]
},
"weight": {
"type": "integer"
}
}
示例输入 🔗︎
medical_notes: A 60-year-old woman diagnosed with arthritis weighs 150 pounds.
示例输出 🔗︎
{
"age": 60,
"gender": "female",
"diagnosis": "arthritis",
"weight": 150
}
个性化回复 🔗︎
任务描述 🔗︎
作为抵押贷款客户服务机器人,您的任务是根据提供的事实为客户问题创建个性化的电子邮件回复。确保回复清晰、简洁且直接解决问题,并以友好的专业语气结束邮件。
已知事实 🔗︎
30-year fixed-rate: interest rate 6.403%, APR 6.484%
20-year fixed-rate: interest rate 6.329%, APR 6.429%
15-year fixed-rate: interest rate 5.705%, APR 5.848%
10-year fixed-rate: interest rate 5.500%, APR 5.720%
7-year ARM: interest rate 7.011%, APR 7.660%
5-year ARM: interest rate 6.880%, APR 7.754%
3-year ARM: interest rate 6.125%, APR 7.204%
30-year fixed-rate FHA: interest rate 5.527%, APR 6.316%
30-year fixed-rate VA: interest rate 5.684%, APR 6.062%
示例输入 🔗︎
email:
Dear mortgage lender,
What's your 30-year fixed-rate APR, and how does it compare to the 15-year fixed rate?
Regards,
Anna
示例输出 🔗︎
Dear Anna,
Thank you for reaching out! Our 30-year fixed-rate APR is 6.484%. In comparison, the 15-year fixed-rate APR is 5.848%. While the 15-year option has a lower APR, it typically requires higher monthly payments due to the shorter loan term.
If you have any further questions or need assistance in choosing the best option for your needs, feel free to reach out!
Best regards,
Lender Customer Support
总结 🔗︎
任务描述 🔗︎
作为评论员,您的任务是对一份新闻通讯进行分析并撰写报告。
步骤 🔗︎
- 总结:用清晰简洁的语言总结新闻通讯的关键点和主题。
- 提出有趣的问题:生成三个独特且发人深省的问题,并对每个问题提供详细解答。
- 撰写分析报告:结合总结和问题的答案,创建一份综合报告。
示例模板 🔗︎
新闻通讯内容 🔗︎
newsletter:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Nulla facilisi. Donec nec nisi euismod, vestibulum sapien vel, bibendum nisl. Sed auctor, nunc id aliquet tincidunt, justo felis ultricies lorem, vel feugiat velit eros vel lectus.
总结 🔗︎
The newsletter discusses key trends in technology adoption, highlighting the rise of AI-driven solutions and their impact on various industries. It also touches upon challenges such as data privacy and workforce adaptation.
有趣的问题 🔗︎
Q: What are the main benefits of AI-driven solutions mentioned in the newsletter?
A: The newsletter highlights that AI-driven solutions improve efficiency, reduce costs, and enable better decision-making through data analysis.: Efficiency improvement, cost reduction, and enhanced decision-making. Q: What challenges are associated with adopting AI technologies?
A: The newsletter mentions data privacy concerns and the need for workforce adaptation as significant challenges in adopting AI technologies.: Data privacy concerns and workforce adaptation. Q: Which industries are most impacted by AI-driven solutions?
A: The newsletter suggests that healthcare, finance, and manufacturing are among the industries most impacted by AI-driven solutions.: Healthcare, finance, and manufacturing.
分析报告 🔗︎
# 分析报告
## 总结
本期新闻通讯探讨了技术采用的主要趋势,重点介绍了人工智能(AI)驱动解决方案的兴起及其对各行业的影响。同时,提到了数据隐私和劳动力适应等挑战。
## 有趣的问题与解答
1. **AI 驱动解决方案的主要优势是什么?**
- **解答**:新闻通讯指出,AI 驱动解决方案可以提高效率、降低成本,并通过数据分析改善决策能力。
- **结论**:效率提升、成本降低、决策优化。
2. **采用 AI 技术面临哪些挑战?**
- **解答**:新闻通讯提到,数据隐私问题和劳动力适应需求是采用 AI 技术的主要挑战。
- **结论**:数据隐私问题和劳动力适应。
3. **哪些行业受 AI 驱动解决方案影响最大?**
- **解答**:新闻通讯认为,医疗保健、金融和制造业是受 AI 影响最大的行业。
- **结论**:医疗保健、金融、制造业。
## 文章总结
> 模型选择: https://chat.qwenlm.ai/c/e4fd1d21-0e7f-47e7-be50-875099f35f3e
```text
帮我组织成更好的markdown格式(内容多的话加上目录),请确保内容不要丢失,可以适当小小补充。所有内容都组织在 Markdown格式中,方便我直接复制使用,请用中文回答
```
读书报告总结 🔗︎
模型选择: https://chat.qwenlm.ai/c/e4fd1d21-0e7f-47e7-be50-875099f35f3e
代码阅读 🔗︎
这段代码实现了什么功能,请给出详细的介绍,画成彩色表格图或者生成可视化图像辅助理解。并输出一份可以运行的最简代码,不需要错误处理,不需要边界场景处理,不需要日志。
如何用好AI 🔗︎
最近在 Youtube 上很火的一个视频
Andrej Karpathy(安德烈·卡帕斯)是一位斯洛伐克裔加拿大计算机科学家,专长于人工智能、深度学习和计算机视觉领域。他于 1986 年 10 月 23 日出生在捷克斯洛伐克布拉提斯拉瓦,15 岁时随家人移居加拿大多伦多。他在多伦多大学获得计算机科学和物理学学士学位,在英属哥伦比亚大学取得硕士学位,随后在斯坦福大学师从李飞飞教授,专攻计算机视觉与自然语言处理交叉领域,并于 2015 年获得博士学位。
职业生涯中,Karpathy 曾是 OpenAI 的创始成员之一,专注于深度学习和计算机视觉研究。2017 年,他加入特斯拉,担任人工智能和自动驾驶视觉总监,领导 Autopilot 计算机视觉团队,直接向埃隆·马斯克汇报。2022 年 7 月,他离开特斯拉,并于 2023 年 2 月宣布重返 OpenAI。
此外,Karpathy 还积极从事教育工作,曾在斯坦福大学开设并主讲深度学习课程 CS231n:卷积神经网络与视觉识别,深受学生欢迎。他也在个人 YouTube 频道上分享关于人工智能和深度学习的教育内容,致力于推动人工智能领域的发展和普及。
2 个多小时的时长,介绍了如何使用 LLM,以下是他用的草图:
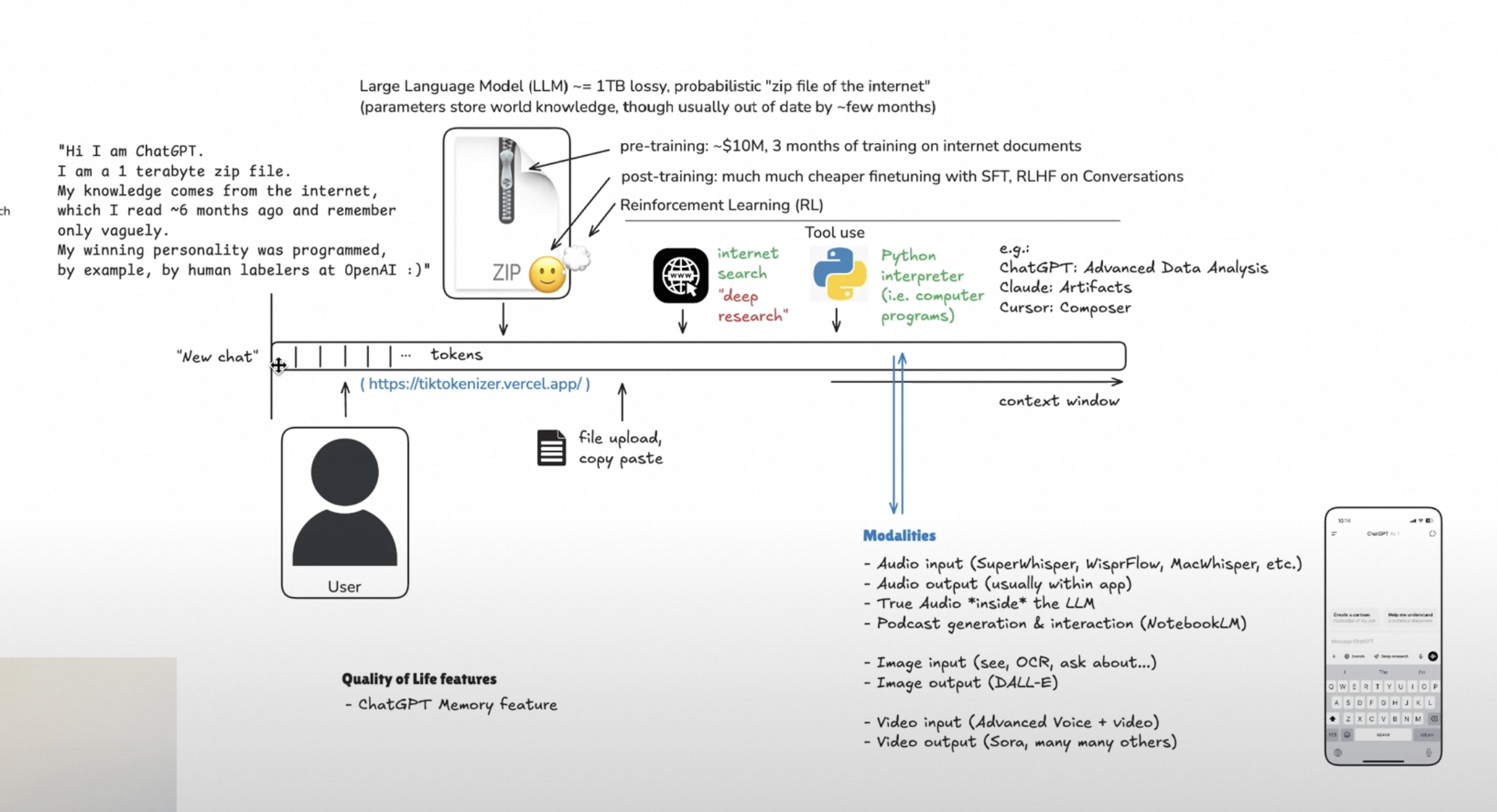
原视频地址:
如何选择合适的模型,各大模型 APP 和对比 🔗︎

大模型竞技场和比较的两个常用网站
leaderboard1 : Chatbot Arena LLM Leaderboard: Community-driven Evaluation for Best LLM and AI chatbots
ChatGPT 本质 🔗︎
Large Language Model (LLM) ~ 1TB lossy, probabilistic “zip file of the internet” (parameters store world knowledge, though usually out of date by few months)
大规模语言模型(LLM)~ 1TB 有损、概率性的“互联网压缩文件”(参数存储了世界知识,但通常会滞后几个月)。
“Hi I am Chat6PT. I am a 1 terabyte zip file. My knowledge comes from the internet, which I read 6 months ago and remember only vaguely. My winning personality was programmed, by example, by human labelers at OpenAI:)”
“你好,我是 ChatGPT。我是一个 1TB 的压缩文件。我的知识来源于互联网上的信息,这些信息是我 6 个月前阅读并只模糊记住的。我的迷人个性是由 OpenAI 的人类标注者通过 Label 标注编程的 :)”
pre-training: -$10M, 3 months of training on internet documents post-training: much much cheaper finetuning with SFT, RLHF, RL on Conversations
预训练:耗资 1000 万美元,使用互联网上的文档进行 3 个月的训练
后训练:更便宜得多的微调,包括 SFT(监督微调)、RLHF(基于人类反馈的强化学习)以及对话强化学习
查看 token 的工具: tiktokenizer
ChatGPT 的用法 🔗︎
ChatGPT 本质上是 Knowledge Based Query, 基于网络的很普遍的知识,不保证一定正确:
1、尽量简短的对话,如果是新话题建议新开聊天。因为tokens很贵,而且话题越长越容易出现错误
2、选择不同的模型去处理不同的任务,比如 Creation、Traveling 这种,同时和不同的模型对话,看结果有何不同
模型的差异 🔗︎
1、思维模型 vs 通用模型: 思维模型擅长编程和数学,一般会比较耗时
2、sonnet 3.5 不是思维模型
Tool Use 🔗︎
- 网络搜索:搜索《白蓮花大飯店》最新季出来的时间
- what are the bigheadline news today ?
- 有用信息: 一个好用的隐私浏览器 brave 隐私浏览器
- DeepSearch:thinking + 网络搜索
- pdf 文档阅读:丢一个文档给 llm 让他总结
- 书籍阅读:《the wealth of nations》,把章节贴给 llm, 然后让它总结一下和问一些问题,特别是那些不熟悉的领域
- 电脑程序:LLM 针对那些无法通过大脑计算回答的问题,会通过借助外部工具,不同 llm 有不同的外部工具
- 比如一个复杂的乘法,ChatGPT 会通过 python 解释器得到结果,然后返回结果
- 数据分析:ChatGPT 功能
- 比如研究 OpenAl 在一段时间内的估值(使用搜索工具),然后创建一个表格,输入每一年的估值。
- Now plot this. Use log scale for y axis 制作一张图
- dive deep: data analaysis with chatgpt
- Artifacts: Claude 模型的功能 claudiartifacts.com
- Flashcards on Adam Smith’s Life and Economic Theories ,然后从维基百科复制 Adam Smith 的内容
- Now use Artifacts feature to write a flashcards app to test me on these. 会生成一个 APP
- 思维导图: 比较喜欢可视化的东西,对书的章节、代码等,通过这种方式能好的理解和 memory
- We are reading The Wealth of Nations by Adam Smith, I am attaching Chapter 3 of Book 1. Please create a conceptual diagram of this chapter.
- Cursor Composer: vibe programming
- setup a new React14 starter project
- when either x or o win, i want confetti or something 制作一个撒花 🎉 的效果
- cmd + k: 内嵌聊天
- cmd + i:composer
- cmd + l: chat
modalities 模式 🔗︎
日常对话通过语音快速输入,60%场景
语音转换为文本的方式沟通:
- 语音输入: superwhisper, wisperflow, macwisper
- 语音输出: app 自带
另外是一种真语音模式: llm 不会转换语音成文本,而是通过语音形式处理。只需要 ChatGPT 开启语音模式即可。
ChatGPT 的语音模式经常会拒绝,比如模仿狐狸的音调,但是 Grok APP 的语音模式通常会直接按照你的要求跟你对话,比如
- which mode you remmend we try out ?
- romantic mode 浪漫模式
- let’s flip to unhinged 发神经模式
- i am going to try the conspiracy mode 串谋模式
- let’s try the sexy mode
podcast generation & interactive 🔗︎
- http://notebooklm.google.com/: 丢一些资源给他,自动生成音频。并且可打断和交互问问题。
- 适合不适合阅读的场景比如途中开车,可以听一些自己感兴趣的领域。
- https://open.spotify.com/show/3K4LRyMCP44kBbiOziwJjb: histories of mysteries podcast 一些生成的音频上传到 spotify
图片 🔗︎
see, ocr, ask about
- 上传图,让模型输出看到的东西,确保输出内容和图一致;问问题, 比如:Longevity Mix Bryan Johnson 的一张营养图, ctr + command + shift + 4: mac 截图
- 上传图,让模型对指定内容,输出特定格式,比如
latex格式 - 上传图,对营养成分进行分析
- 解释
meme图。meme 中文是迷因,指「网络爆红事物」的意思
生成图 🔗︎
Dall - e- ChatGTP: what are the bigheadline news today ? generate an image summarizes today.
- https://ideogram.ai/: 生成一些视频的封面
视频 🔗︎
- video input: advanced voice + video 可以通过开启视频,然后直接和模型对话,问一些问题
- video output: sora …
大模型的 memory feature 🔗︎
一般对话后,重新开 chat,大模型对于之前的记忆会抹去(当然有时会自动触发记忆)。我们可以主动要求大模型记住,并且可以管理记忆。
- can you please remember this ? 这样会记住你们的对话
custom instructions 🔗︎
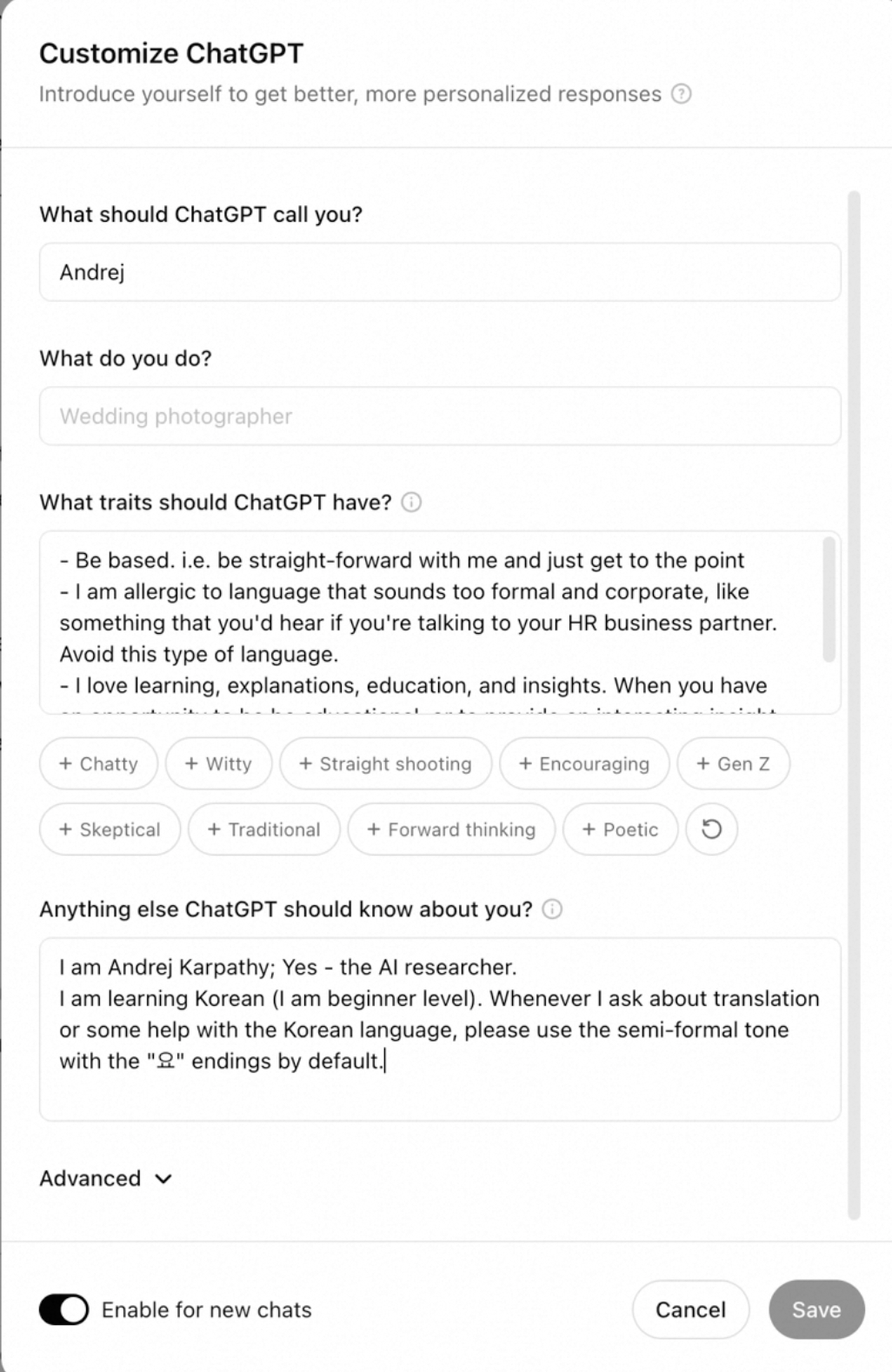
ChatGPT instructions
custom chatgpt 🔗︎
chatgpt 翻译比一般的翻译更好,比如https://papago.naver.com/ 。 我们可以自定义翻译能力,比如对句子拆分,逐字解释
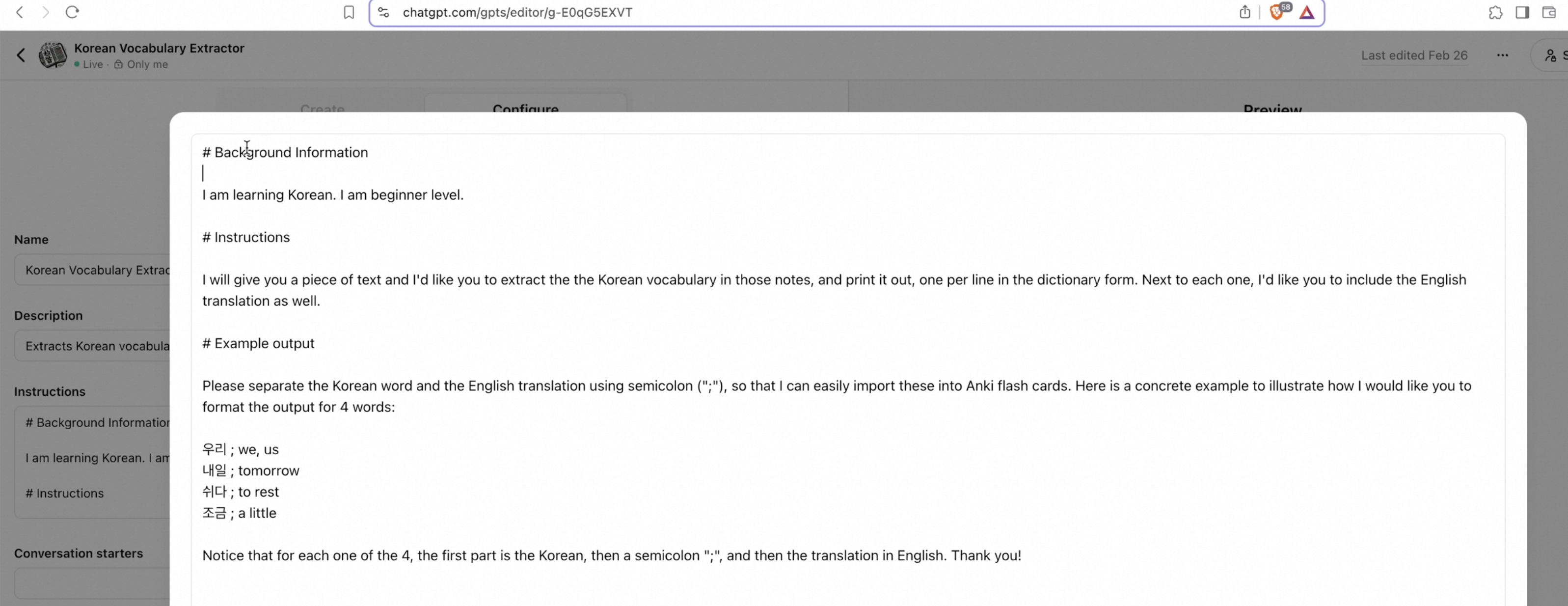
custom ChatGPT
对电影的字幕进行解释:
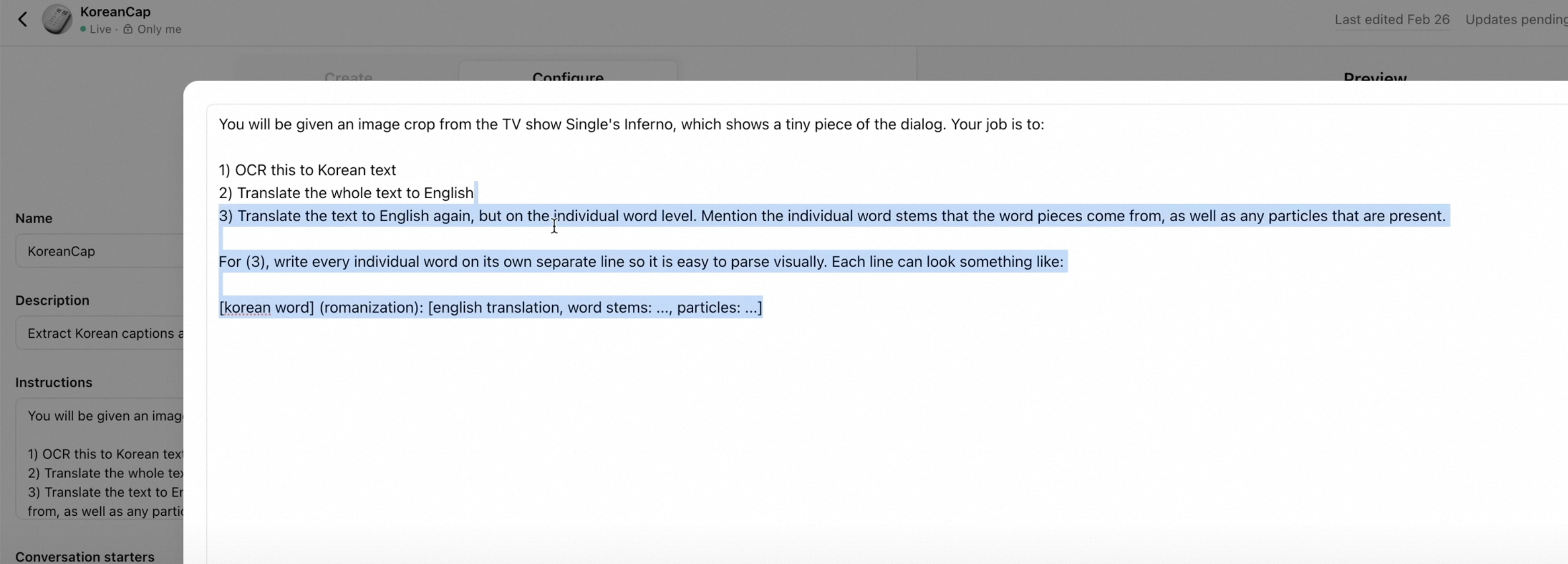
ChatGPT OCR
这里还有一个方案,就是用谷歌智能眼镜对文字 ocr,然后丢给 chatgpt

自己搭建一个cursor 🔗︎
安装vscode 插件:

Cline 插件
AI 工具和资源 🔗︎
1. 图像与 Prompt 工具 🔗︎
图像放大 🔗︎
- BigJPG
- 提供高质量图像放大服务。
Prompt 工具 🔗︎
- MidJourney Web Editor
- 在线编辑和优化 MidJourney 的 Prompt。
- Prompt 指南:
Prompt 框架 🔗︎
- 概述:角色/背景
- 过程:技能/规则/流程(上下文)
- 依赖:工具/知识/素材(例子)
- 控制:正向/负向要求(要求)
2. Agent 工具 🔗︎
多 Agent 协作 🔗︎
- 任务拆解与择优:
- ChatGPT GPTs
- Coze
- Dify 文档
- 双向费曼助手:用于高效学习与知识传递。
文档对话与知识库 🔗︎
3. 绘图工具与工作流 🔗︎
IP 形象设计 🔗︎
- 素材分类:
- IP + 场景 / IP / IP + 纯背景
- 打标工具:
- [BooruDatasetTagManager]
- 角色类格式:触发词 + 主体 + 情绪 + 动作 + 服装 + 视角
- 场景类格式:触发词 + 主题 + 情绪 + 动作 + 服装 + 环境描述 + 光影 + 视角 + 景别
- [BooruDatasetTagManager]
- 模型推荐(Liblib):
- NOVA SDXL 1.0
- NOVA 3D 立体
- NOVA 真实 HYPER
- 参数调整:
- 过拟合 / 牵拟合 / 泛化化 / 正则化
- 工作流:
- 静态输出:SD + PS + KR
- 动态演绎:RW + CC
- 音效处理:AE
- 姿势调整:ControlNet + OpenPose
- Flux 工作流
4. AI 编程工具 🔗︎
- CopyCoder.ai
- AI 辅助编程工具。
Git Copilot 能力 🔗︎
- 授业、解惑(无私心、耐心)。
- 提供解决方案(环境准备等)。
- 理解语义。
- 调用函数。
- 图片理解。
场景特征 🔗︎
- 广泛、高频、反馈快速、目的函数明确、中低决策维度。
5. AI 协作方式 🔗︎
- 非结构化数据的结构化
- One Shot:知识 + 已知;求解
- Fine-Tune:调优(不做标记)
- 示例:我在北京天(安门)天(气) -> Pattern 识别或压缩
- 多层结构:人类的语言包含了人类的一切智慧。
- 文本模型:Long-Chain?
6. AI 应用案例 🔗︎
盒马 SKU 推荐 🔗︎
- 算法不重要:4000 SKU,动销商品底池不多。
- AI 的机会:快速数字化,降低物理界建模成本(非结构化 -> 结构化)。
- 抖音 vs 快手:让小姐姐通过视频 + 音频快速发视频,从助手角度出发,解决用户问题,而非单纯价格便宜(小心高维打低维)。
7. AIGC 启发 🔗︎
- 高质量输入:需要高质量的数据输入。
- 输出依赖:依靠人的抽象归纳能力、第一性原理推理能力(人与人之间最大的区别)。
- Seed Science AI:SeedScienceAI
8. 语音识别与短课程 🔗︎
- Moonshine Web:语音识别工具。
- DeepLearning.AI 短课程:
- Ideogram:Ideogram
9. 短视频 AI 工具 🔗︎
- Stable Diffusion + Ebsynth Utility + 绘世:短视频 AI 制作工具组合。
10. 参考视频 🔗︎
fastrtc 🔗︎
AI工具 🔗︎
chatwise 阿里云deepseek r1 Gemini 2 Flash Thinking
repomix 打包代码
你先不要着急回答我的问题,为了质量更高的答案,我还需要补充哪些信息
书籍 🔗︎
《风险投资史》 《天下格局》 《a brief history of inteligency》 《第一只眼》